Modernized knowledge portfolio
A streamlined front door for technical depth.
The original mathematics archive is still here, but the experience now starts with clearer pathways into Ryan's projects, learning tracks, and professional background.
Featured work
Project pathways with practical outcomes
A curated entry point into analytics, finance, machine learning, and standalone application work.
Data Dashboard
Interactive business intelligence work focused on reporting, representation, and analytical storytelling.
ExploreAI Finance
Applied machine learning and algorithmic-finance learning space connecting models, markets, and decision support.
ExploreQuick Start Finance
Standalone finance app experience preserved alongside the modern Astro shell for practical exploration.
ExploreExplore the library
Learning tracks for math, data, and immersive education
The site can scale as a dynamic system by organizing deep content into reusable cards and guided sections.
Mathematics Library
Algebra, precalculus, mathematicians, and machine-learning foundations rendered with a modern reading experience.
ExploreData & Machine Learning
Notes and projects spanning data science, machine learning, dashboards, and AI-assisted finance workflows.
ExploreImmersive Education
Virtual reality, education technology, and multidisciplinary learning experiences for technical audiences.
ExploreOriginal archive
Machine learning mathematics notes
The preserved long-form math content remains available below for continuity while the top of the site now offers a more professional landing experience.
Open the full mathematics archive
"Mathematics requires a small dose, not of genius, but of an imaginative freedom which, in a larger dose, would be insanity." — Angus K. Rodgers
Noteworthy Machine Learning Algorithms
Machine Learning ⇒ software able to detect patterns, make decisions, predict outcomes, learn from mistakes & optimize own performance without being explicitly programmed to do so
Supervised Learning
Learning a function that maps to an output based on the example of
input-output pairs. In other words, training a model on data where the
outcome is known, for subsequent application to data where the outcome
is not known."
"Present labeled examples to learn from. For instance, when we want
to be able to predict the selling price of a house in advance in a real estate
market, we can get the historical prices of houses and have a supervised
learning algorithm successfully figure out how to associate the prices to the
house characteristics.
Using the uppercase letter X we intend to use matrix notation,
since we can also treat the y as a response vector (technically a
column vector) and the X as a matrix containing all values of the feature
vectors, each arranged into a separate column of the matrix. . . . building
a function that can answer the question about how X can imply y
. . . [with] a functional mapping that can translate X values into
y without error or with an acceptable margin of error. . . . to
determinate a function of the following kind:" (Massaron, pg 24)
-
Active Learning
Semi-supervised learning algorithm where the software picks examples of data that are most useful to its learning & ignoring the bulk of data in data warehouses or data lakes.
-
Online Learning
In a fast-paced environment, a learning algorithm may stream data as it becomes available, continuously adapting to any new associations between predictive variables & the response.
-
Matrix Notation Function
"When the function is specified, and we have in mind a certain algorithm with certain parameters & an X matrix made up of certain data, conventionally we can refer to it as a hypothesis."
↳ where:
X = a matrix of size (n, p)
y = a response vector of size n
n = # of observations
p = # of variablesStore the predictive variables (features or attributes) in the X matrix, size n x p:
-
Linear Regression | Predict Real Values
Estimate or predict real values based on continuous variables -> establish relationship between independent variables (matrix of features) & dependent variable (output) by fitting a best line
-
Homoscedasticity
"Homoskedastic . . . refers to a condition in which the variance of the residual, or error term, [that is, the “noise” or random disturbance in the relationship between the independent variables and the dependent variable], in a regression model is constant. That is, the error term does not vary much as the value of the predictor variable changes." Investopedia
-
Multicollinearity
"[R]efers to predictors that are correlated [, that is, highly linearly related,] with other predictors. Multicollinearity occurs when your model includes multiple factors that are correlated not just to your response variable, but also to each other. In other words, it results when you have factors that are a bit redundant." Minitab
-
No Free Lunch Theorems (NFL)
"[S]tate that any one algorithm that searches for an optimal cost or fitness solution is not universally superior to any other algorithm. . . . 'If an algorithm performs better than random search on some class of problems then in must perform worse than random search on the remaining problems.'” Medium
-
Parsimonious Model
"Parsimonious models are simple models [with the least assumptions & variables but] with great explanatory predictive power. They explain data with a minimum number of parameters, or predictor variables. The idea behind parsimonious models stems from Occam's razor, or 'the law of briefness' (sometimes called lex parsimoniae in Latin)." Statistics How To
-
Law of Large Numbers
As the # of experiments grows, so increases the likelihood that the average of their results will reporesent the true value of the population.
-
Linear Combination
A sum where each addendum value is modified by a weight (the coefficients), and, therefore, a smarter form of summation.
-
Family of Linear Models or Generalized Linear Model (GLM)
Function that specifies the relationship between the X, the predictors, & the y, the target, is a linear combination of the X values. By means of special link functions proper transformation of the answer variable, proper constraints on the weights & different optimization procedures (the learning procedures), GLM can solve a very wide range of problems.
-
Probability Density Function (PDF)
A function describing the probability of values in the distribution. For a normal distribution:
-
Moments of the PDF
-
First moment: expected value or a generalization of the weighted average, the arithmetic mean
-
Second central moment: variance or expectation of the squared deviation of a random variable
-
Third standardized moment: skewness or a measure of the asymmetry of the probability distribution of a real-valued random variable about its mean
-
Fourth standardized moment: kurtosis or a measure of the "tailedness" of the probability distribution of a real-valued random variable
-
-
-
Covariation vs. Correlation
Covariation is a measure of association that is affected by the scale of the variables & is not standardized. When a variable is standardized, it returns a value between -1 to 1, -1 being negatively correlated (one grows, the other shrinks), 1 being positively correlated (one grows, so does the other) & 0 meaning there is no relationship, at all.
Correlation is a measure of the strength of linear association between two variables, of how close to a straight line your points are.-
Covariance Expression
-
Pearson's Correlation
-
-
Ordinary Least Squares (OLS)
Another way to refer to linear regression. "A type of linear least squares method for estimating the unknown parameters in a linear regression model. OLS chooses the parameters of a linear function of a set of explanatory variables by the principle of least squares: minimizing the sum of the squares of the differences between the observed dependent variable (values of the variable being observed) in the given dataset and those predicted by the linear function of the independent variable. Geometrically, this is seen as the sum of the squared distances, parallel to the axis of the dependent variable, between each data point in the set and the corresponding point on the regression surface—the smaller the differences, the better the model fits the data." Wikipedia
-
Bias
The point at which a regression line crosses the y-axis; that is, the predicted value when X = 0.
bias = y-intercept
-
Derivation of Line of Best Fit | Residual Sum of Squares(RSS)
Linear regression tries to fit a line through a given set of points, choosing the best fit. The best fit is the line that minimizes the summed squared difference between the value dictated by the line for a certain value of x and its corresponding y values. It is optimizing the squared error.
RSS = Σ(y - ŷ)2 → min
-
Residuals or Errors
The difference between the observed values of the dependent variable (y) & the predicted (fitted) values (ŷ).
"The deviations of the actual y from the predicted y. When forming a linear regression, the predicted Y follows a linear relationship. Deviations from this line, are called residuals; they measure the distance between the actual Y for each N and the line (predicted Y). For a good linear model, the residuals should be small and random. If they are really large it shows the model is not very accurate, and if there is a pattern then it would suggest a non-linear model would fit better for example." r/AskStatistics- Each data point has to residuals.
- Both the sum & the mean of the residuals are equal to zero.
- If the points in a residual plot are randomly dispersed arount the horizontal axis, the linear regression model is appropriate. Otherwise, a non-linear model is more appropriate.
- Positive residual ⇒ better than expected predicted value.
- Negative residual ⇒ less than expected predicted value.
- Zero residual ⇒ meets the expected value.
- Residual Sum of Squares ⇒ used to measure the amount of variance in a dataset not explained by the model.
- Standard Error of Residuals ⇒ the smaller, the more accurate the predictions are.
-
Fitted Values or Predicted Values
The estimates Ŷi obtained from a regression line, the predictions.
-
Interpolation & Extrapolation
Interpolation: A linear regresssion model can always work within the range of values from which it learned. Extrapolation: But can provide correct values for its learning boundaries only in certain conditions.
-
Kurtosis
This is a measure of the shape of the distribution of the residuals. A bell-shaped distribution has a zero measure. A negative value points to a too flat distribution; a positive one has too great a peak.
"A measure of the 'tailedness' of the probability distribution of a real-valued random variable." Wikipedia -
Simple Linear Regression
Combining one variable in an equation to predict a single outcome
y = b0 + b1x1
or
y = βx + β0
or
y = mx + b
or
y = a + bx
or
Yi = b0 + b1Xi + ei
↳ where:
y = response, dependent, criterion, target, outcome, label
a, b, b0, β0 = constant, y-intercept, bias
m, b, b1, β = slope, coefficient, gradient, angular coefficient
x, x1, Xi = independent, explanatory, predictor variable, matrix of predictors, feature vector, control variable
ei = explicit error term
-
Minimization of the Cost Function
"The search for a line's equation that it is able to minimize the sum of the squared errors of the difference between the line's y values and the original ones." WGU MSDA
Methods of minimization include Pseudoinverse, QR factorization, & gradient descent.-
Regression Function of h(X):
Cost function minimized as follows:
-
Pseudoinverse
An analytical formula for solving a regression analysis and getting a vector of coefficients out of data, minimizing the cost function:
Or solve for w in linear equations called normal equations:
-
-
Gradient Descent
"Explaining it simply, it resembles walking blind in the mountains. If you want to descend to the lowest valley, even if you don't know and can't see the path, you can proceed approximately by going downhill for a while, then stopping, then going downhill again and so on, always aiming at each stage for where the surface descends until you arrive at a point when you cannot descend anymore. Hopefully, at that point you will have reached your destination.
. . . Though quite conceptually simple (it is based on an intuition that we have surely applied ourselves to move step-by-step, directing where we can optimize our result), gradient descent is very effective and indeed scalable when working with real data. Such interesting characteristics have elevated it to the core optimization algorithm in machine learning; it is not limited to just the linear model family, but it can also be extended, for instance, to neural networks for the process of back propagation, which updates all the weights of the neural net in order to minimize training errors. Surprisingly, gradient descent is also at the core of another complex machine learning algorithm, gradient boosting tree ensembles, where we have an iterative process minimizing the errors using a simpler learning algorithm (a so-called weak learner because it is limited by a high bias) to progress towards optimization." (Massaron, p. 62)
"A gradient is the slope of a function. It measures the degree of change of a variable in response to the changes of another variable. . . [It] is a convex function whose output is the partial derivative of a set of parameters of its inputs. The greater the gradient, the steeper the slope." GeeksForGeeks-
Cost Function
-
Final Resolution Form
-
Learning Rate (α)
Very important in the process, because, if it is too large, it may cause the optimization to detour & fail.
-
-
Feature Scaling
"[S]ome features in your data may be represented by measurements in units, some in decimals, & others in thousands, depending on what aspect of reality each feature represents. In our real estate example, one feature could be the number of rooms, another one could be the percentage of certain pollutants in the air, and finally, the average value of a house in the neighborhood. When it is the case that the features have a different scale, though the algorithm will be processing each of them separately, optimization will be dominated by the variables with the more extensive scale. Working in a space of dissimilar dimensions will require more iterations before convergence to a solution (& sometimes there might be no convergence at all).
&emps; The remedy is very easy; it is just necessary to put all the features on the same scale . . . Feature scaling can be achieved through standardization or normalization. Normalization rescales all the values in the interval between zero & one (usually, but different ranges are also possible), whereas standardization operates by removing the mean & dividing by standard deviation to obtain a unit variance." (Massaron, p. 76) -
Multiple Linear Regression (MLR)
Combining many variables in an equation to predict a single outcome
or
or
↳ where:
E(Y), Y, Y’, Ŷ = Expected value of Y or instance of Y
a, β0 = constant, y-intercept
β0, β1, β2, β3 = population regression parameters, coefficients
X1, X2, X3 = independent, explanatory, predictor variables, covariates, IVs
ε = regression error term, an adjustment term-
Vector of Standardized Coefficients & Bias
-
Transformation of Predictors
↳ where:
x̄ = original mean
δ = original variance -
Variable(s) Interactions
"One of the first sources of non-linearity is due to possible interactions between predictors. Two predictors interact when the effect of one of them on the response variable varies in respect of the values of the other predictors. . . .[I]nteraction terms have to be multiplied by themselves for our linear model to catch the supplementary information of their relation as expressed in this example of a model with two interacting predictors." (Massaron, p. 87)
-
-
Polynomial Linear Regression
"[G]enerally used when the points in the data are not captured by the Linear Regression Model and the Linear Regression fails in describing the best result clearly." Anaylytics Vidhya
"Although this model allows for a nonlinear relationship between Y and X, polynomial regression is still considered linear regression since it is linear in the regression coefficients." PSU
"As an extension of interactions, polynomial expansion systematically provides an automatic means of creating both interactions and non-linear power transformations of the original variables. Power transformations are the bends that the line can take in fitting the response. The higher the degree of power, the more bends are available to fit the curve." (Massaron, p. 89)y = b0 + b1x1 + b2x22 + . . . + bnxnn
-
Overfitting
"[F]itting the data at hand so well that the result is far from being extraction of the form of the data to draw predictions from; the model won't learn general rules but it will just be memorizing the dataset itself in another form." (Massaron, p. 94)
In other words, f̂(x) fits the training set noise. -
Underfitting
When f̂ is not flexible enough to approximate f.
-
Coefficient of Determination | R Squared (R2) | Goodness of Fit Parameter
"[T]he R2 value basically depicts how correlated a certain trend is, which means how related two variables are. If you plot x & y on a scatterplot, & we note a correlation of r, the R2 is the amount of variation in y that can be predicted by x. So it is the percentage of variation that variable x can predict in variable y, which effectively means that if y changes by a percentage p, then x can still predict that change in y. It is usually expressed in percentage, so the closer your R2 value is to 100% [(expressed in decimal from 0 to 1)], the more accurately x predicts y, & therefore the more correlated your data is." ELI5
- A metric to describe variation in outcome explained by the IVs.
- Mostly, R2 will increase as more predictors are added to the model.
- By itself R2 cannot identity which Predictors should be included in the model.
- If R2 is 0, none of the IVs predict outcome. A value of 1 means that the outcome can be predicted without error.
R2 = 1 - SSres/SStot
↳ where:
- ↳ SStot = Σ(y - yavg)2
-
Adjusted R Squared
Adj R2 = 1 - (1 - r2) * [(n - 1)/(n - p - 1)]
↳ where:
-
↳ p = number of regressors
↳ n = sample size -
Support Vector Regression
Use as a regression method, maintaining all the main features that characterize the algorithm (maximal margin). The Support Vector Regression (SVR) uses the same principles as the SVM for classification, with only a few minor differences.
-
Epsilon-Insensitive Tube
-
The Gaussian RBF Kernel
-
-
Logistic Regression
A classification algorithm used to estimate discrete values, binary values (0/1, yes/no, true/false) based on given set of independent variables; predicts probability between 0 & 1 as output values.
Like its name is logarithmic. Its graph is curvilinear. The dependent variable may be binomial, ordinal or multinomial. If the dependent variable is binary, the graph is sigmoid. If not, the graph can be more pronounced, parabolic, etc.
Models are fitted using the method of maximum likelihood - i.e. the parameter estimates are those which maximize the likelihood of the data which have been observed.-
Logistic Regression Algorithm Formula
-
Logistic Model
-
Assumptions
-
Based on Bernoulli (also, Binomial or Boolean) Distribution rather than Gaussian because the dependent variable is binary.
-
The predicted values are restricted to a range of nomial values like 'Yes', 'No', S, M, L, etc.
-
It predicts the probability of a particular outcome rather than the outcome itself.
-
There are no high correlations (multicollinearity) among predictors.
-
It is the logarithm of the odds of achieving 1. In other words, a regression model, where the output is natural logarithm of the odds, also known as 'logit'.
-
Sample Size Minimum
According to Peduzzi, et al (1996) use the following guidlines for minimum # of cases. Let p be the smallest of the proportions of negative or positive cases in the population, & k be the # of covariates (IVs). According to Long (1997), if the result is < 100, increase it to 100.
↳ where:
N = Minimum number of cases
k = # of covariates
p = Smallest proportions of negative/positive cases -
Binary Classification Problem
An n-dimensional feature vector (xi) paired with its label.
The output can be either "0" or "1". What if we check the probability of the label belonging to class "1"? More specifically, a classification problem can be seen as: given the feature vector, find the class (either 0 or 1) that maximizes the conditional probability.
-
Classification Function
The underlying model may be linearor non-linear.
-
-
Sigmoid Function | Predicting Probability (p̂)
It is predictive, but only of the probability. It is used to model the probability of a certain class or event existing such as pass/fail, win/lose, alive/dead ore healthy/sick.
See logit & sigmoid functions at Nathan Brixius.
or
-
Maximum Likelihood Estimation (MLE)
"A method of estimating the parameters of a probability distribution by maximizing a likelihood function." Wikipedia
-
Stochastic Gradient Descent (SGD)
"[S]tochastic means a system or a process linked with a random probability. . . . [So], a few samples are selected randomly instead of the whole data set for each iteration. . . . [T]he term batch denotes the total number of samples from a dataset that is used for calculating the gradient for each iteration." GeeksForGeeks
-
McFadden's R2
A default pseudo or simulated R2, McFadden's "denotes the corresponding value but for the null model – the model with only an intercept & no covariates. It will be close to zero, as we would hope." The Stats Geek
↳ where:
Lc = the maximum likelihood value from the current fitted model
Lnull = the corresponding value but for the null value - the model with only an intercept & no covariates -
Confusion Matrix
"A confusion matrix is a summary of prediction results on a classification problem. The number of correct and incorrect predictions are summarized with count values and broken down by each class." MachineLearningMastery
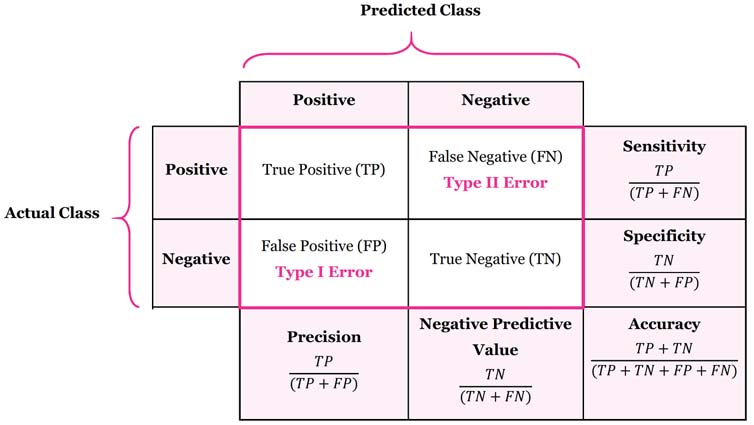
source
-
Accuracy
An error measure of the confusion matrix that is percentage of correct classifications, over the total number of samples.
-
Precision - Positive Predictive Value (PPV)
Considers only one label and counts the percentage of correct classifications on that label.
-
"Precision is undefined for a classifier which makes no positive predictions, that is, classifies everyone as not having diabetes."
-
"When the threshold is very close to 1, precision is also 1, because the classifier is absolutely certain about its predictions."
-
"Precision & recall do not take true negatives into consideration."
↳ High Precision = Not many false positives predicted as your positive case -
-
Recall - Sensitivity - True Positive Rate (TPR)
If precision is about the quality of what you got (that is, the quality of the results marked with the label 1), recall is about the quality of what you could have gotten—that is, how many instances of 1 you've been able to extract properly.
- "A recall of 1 corresponds to a classifier with a low threshold in which all females who contract diabetes were correctly classified as such, at the expense of many misclassifications of those who did not have diabetes."
↳ High Recall = Predicted most of positive case of interest correctly -
F1 Score
The harmonic mean of precision & recall.
-
False Positive Rate (FPR)
-
-
ROC (Receiver Operating Characteristics) Curve
"[The] receiver operating characteristic (ROC) curve is a graph showing the performance of a classification model at all classification thresholds. This curve plots two parameters." Google ML Crash Course
-
AUC (Area Under the ROC Curve)
"AUC provides an aggregate measure of performance across all possible classification thresholds. One way of interpreting AUC is as the probability that the model ranks a random positive example more highly than a random negative example." Google ML Crash Course
-
Variance Inflation Factor (VIF)
"[U]sed to detect the presence of multicollinearity . . . VIF measure[s] how much the variance of the estimated regression coefficients are inflated as compared to when the predictor variables are not linearly related." Medium
-
Akaike Information criterion (AIC)
"[A] single number score that can be used to determine which of multiple models is most likely to be the best model for a given dataset. It estimates models relatively, meaning that AIC scores are only useful in comparison with other AIC scores for the same dataset. A lower AIC score is better." AIC is derived from frequentist probability. TowardDataScience
↳ where:
L = likelihood
k = # of parameters -
Bayesian Information Criterion (BIC)
"[A] criterion for model selection among a finite set of models. It is based, in part, on the likelihood function, & it is closely related to AIC. . . . The BIC resolves this problem by introducing a penalty term for the number of parameters in the model." BIC is derived from Bayesian probability. Analyttica Datalab
↳ where:
L̂ = maximized value of likelihood function of the model
n = # of data points
k = # of free parameters to be estimated -
Root Mean Squared Error (RMSE)
"The standard deviation of the residuals (prediction errors). Residuals are a measure of how far from the regression line data points are; RMSE is a measure of how spread out these residuals are. In other words, it tells you how concentrated the data is around the line of best fit." StatisticsHowTo
-
-
Lasso Regression
The Lasso algortihm performs regularization by adding to the loss function a penalty term of the absolute value of each coefficient multiplied by some alpha. This is also known as L1 regularization because the regularization term is the L1 norm of the coefficients.
Similar to Ridge Regression & can be used to select important features of dataset; shrinks the coefficients of less important features to exactly 0. -
Ridge Regression
Regularized regression where large coefficients are penalized (to avoid over-fitting)
-
Hyperparameter Tuning
Choosing a set of optimal hyperparameters for a learning algorithm. For example, picking an alpha parameter (α) for Ridge Regression loss function.
-
Regularization
"In mathematics, statistics, finance, computer science, particularly in machine learning and inverse problems, regularization is the process of adding information in order to solve an ill-posed problem or to prevent overfitting. Regularization can be applied to objective functions in ill-posed optimization problems." Wikipedia
-
L1 Regularization Norm
Σ
-
L2 Regularization Norm
Σ
↳ where:
-
↳ α = constant parameter we choose to
penalize for large magnitudes of coefficients (similar to picking
k in k-NN) & controls model complexity
↳ a = coefficients of linear model
↳ OLS = Ordinary Least Squares -
Elastic Net Regularization
The penalty is a linear combination of the L1 & L2 penalties.
-
Classification & Regression Trees (CART)
A sequence of if/else questions about individual features with the objective of inferring labels. Trees are capable of capturing non-linear relationships between features & labels. Trees do not require feature scaling such as standardization.
-
Decision Tree
A data structure consisting of a hierarchy of Nodes (questions or predictions):
-
Nodes
Grown recursively - based on the known state of its predecessors.
-
Root
It is the position at which the decision tree starts growing; has no parent node & is a question giving rise to two children nodes.
-
Internal Node
Has one parent & gives rise to two children.
-
Leaf
Has one parent node & no children; it is where a prediction is made.
-
-
Maximum Depth
Maximum # of branches separating the top from an extreme end.
-
Decision Region
Region in the feature space where all instances are assigned to one class label.
-
Decision Boundary
Surface separating different decision regions.
-
Information Gain
"Information gain is the reduction in entropy or surprise by transforming a dataset and is often used in training decision trees. Information gain is calculated by comparing the entropy of the dataset before and after a transformation" MachineLearningMastery; it is a ratio of information gain to the intrinsic information.
↳ where:
f = feature
sp = split point
impurity criteria = measured via gini index, entropy -
Generalization Error
Does f̂ generelize well to unseen data?
↳ where:
irreducible error = contribution of noise -
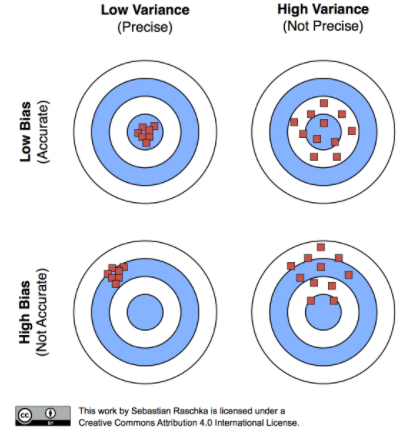
Bias
Bias is an error term that tells you, on average, how much f̂ ≠ f.
-
High-bias models lead to underfitting.
-
-
Variance
Variance tells you how much f̂ is inconsistent over different training sets.
-
High-variance models lead to overfitting.
-
-
Model Complexity
Sets the flexibility to approximate the true function of f̂.
-
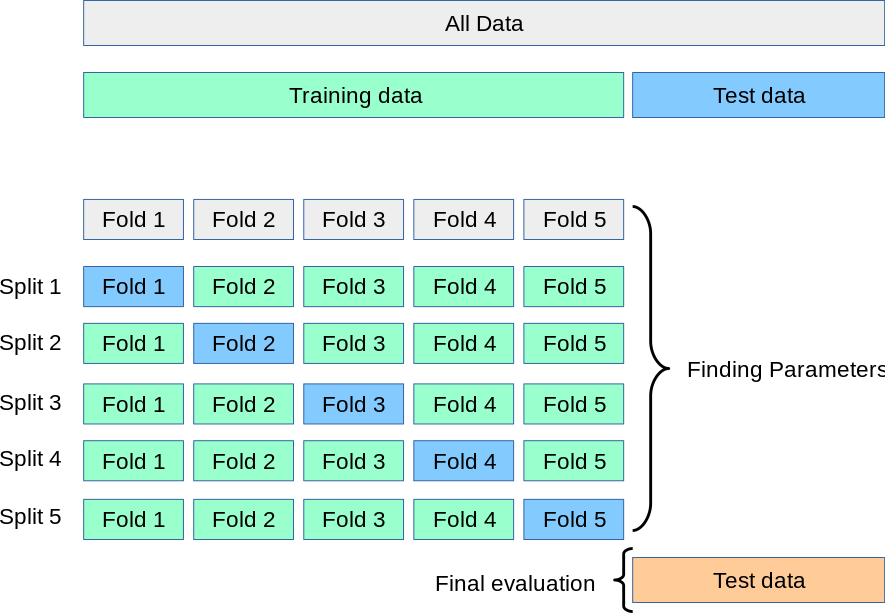
Cross-Validation
"a resampling procedure used to evaluate machine learning models on a limited data sample. ... That is, to use a limited sample in order to estimate how the model is expected to perform in general when used to make predictions on data not used during the training of the model." MachineLearningMastery
To combat limited ability with current dataset to generalize to unseen data.-
K-Fold CV Error
-
-
Decision Tree Regression
Supervised learning algorithm used for classification problems; works for categorical & continuous variables
-
Standard Deviation Reduction
F(T, X) = ΣP(c)S(c)
-
-
Limitations of CARTs
-
Classification: can only produce orthogonal decision boundaries.
-
Sensitive to small variations in the training set.
-
High variance: unconstrained CARTs may overfit the training set.
-
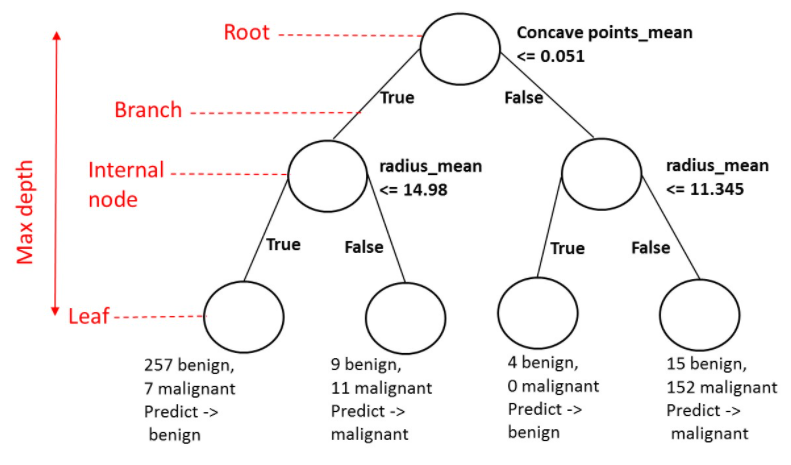
source
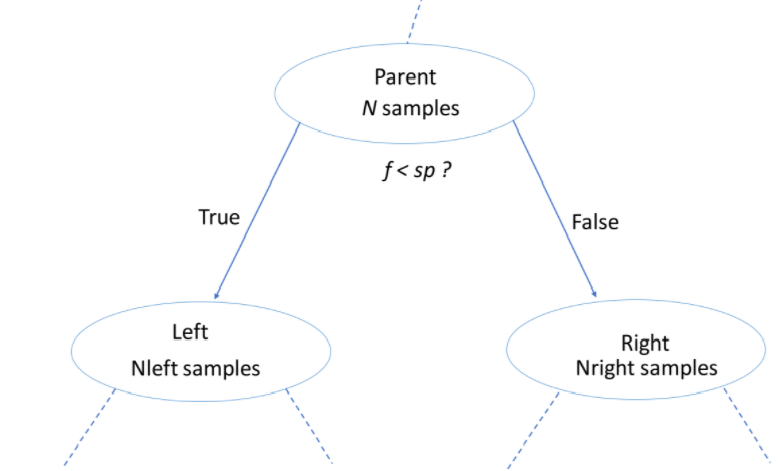
source
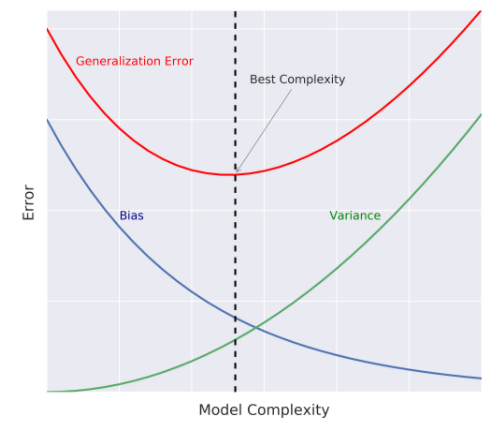
source
source
source
Ensemble Learning
Ensemble methods use multiple learning algorithms to obtain better predictive performance than could be obtained from any of the constituent learning algorithms alone.
-
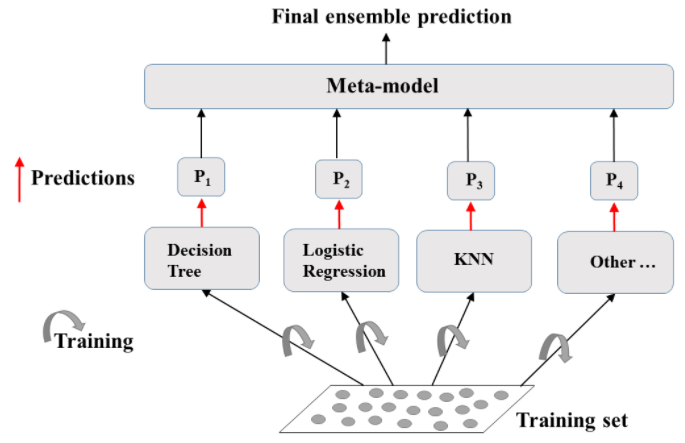
Voting Classifier
-
Train different models on the same datset.
-
Let each model make its predictions.
-
Meta model: aggregates predictions of individual models.
-
Final prediction: more robust & less prone to errors.
-
Best results: models are skillful in different ways.
-
-
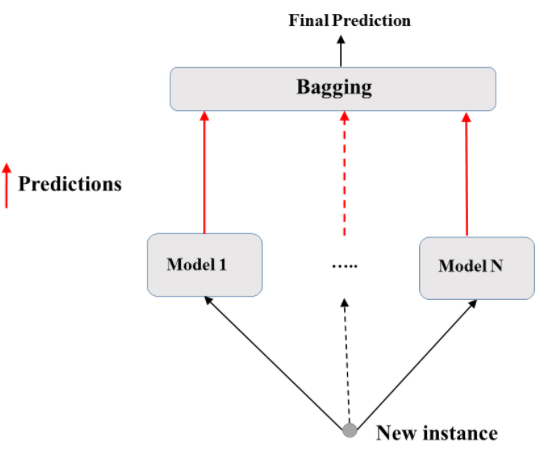
Bagging: Bootstrap Aggregating
-
Train different subests of the same training set with same algorithm in N models.
-
Base estimator: Decision Tree, Logistic Regression, Neural Net . . .
-
Each estimator is trained on a distinct bootstrap sample of the training set.
-
Estimators use all available features for training & prediction.
-
Reduces variance of individual models in the ensemble.
-
-
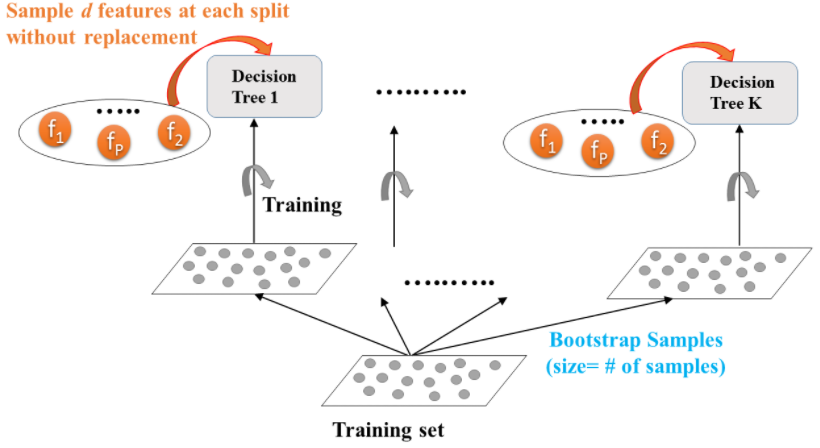
Random Forests
-
Base estimator: Decision Tree
-
Each estimator is trained on a different bootstrap sample having the same size as the training set.
-
Introduces further randomization in the training of individual trees.
-
d features are sampled at each node without replacement.
↳ where: d < total # of features
-
-
Boosting
Ensemble method combing several weak learners to form a strong learner.
↳ where: weak learner = slightly better than random guessing ⇒ the proverbial dart-throwing monkey.-
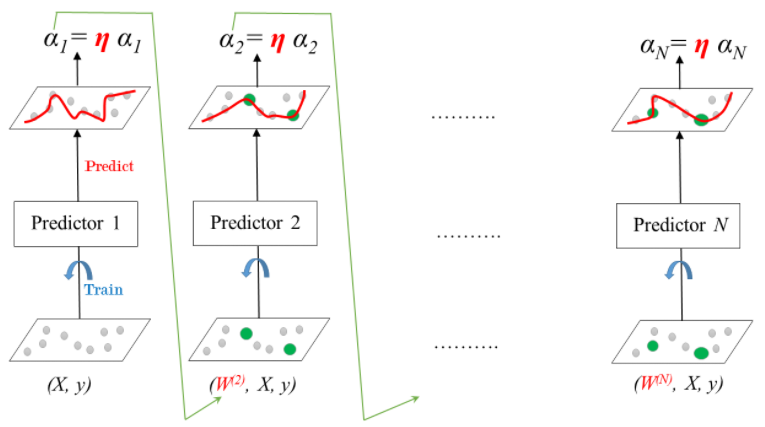
AdaBoost: Adaptive Boosting
-
Each predictor pays more attention to the instances wrongly predicted by its predecessors.
-
Achieved by constantly changing the weights of training instances.
-
Each predictor is assigned a coefficient α.
-
α depends on the predictor's training error.
-
Leanring Rate: 0 < η ≤ 1
-
-
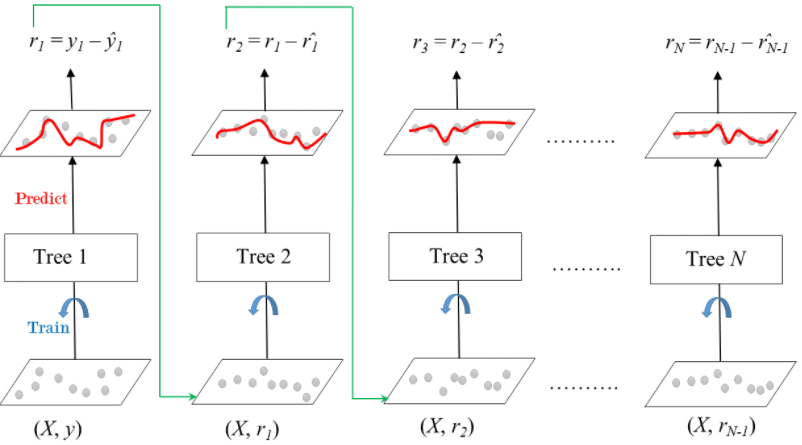
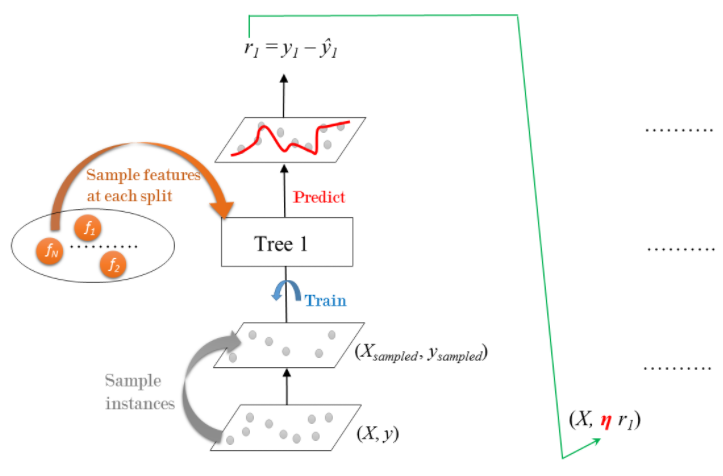
Gradient Boosting
-
Sequential correction of predecessor's errors.
-
Does not tweak the weights of training instances.
-
Fit: each predictor is trained using its predecessor's residual errors as labels.
-
Gradient Boosted Trees: a CART is used as base learner.
-
-
Stochastic Gradient Boosting
-
Each tree is trained on a random subset of rows of the training data.
-
The samples instances (40%-80% of the training set) are sampled without replacement.
-
Features are sampled (without replacement) when choosing split points.
-
Result: further ensemble diversity.
-
Effect: adding further variance to the ensemble of trees.
-
source
source
source
-
-
Hyperparameters
Parameters are learned from data & include CART examples such as split-point of node & split-feature of node. Hyperparameters are not learned from the data & must be set prior to training. CART examples include maximum depth, minimum samples leaf & splitting criterion.
Approaches include:-
Grid Search
-
Manually set a grid of discrete Hyperparameter values.
-
Set a metric for scoring model performance.
-
Search exhaustively through the grid.
-
For each set of hyperparameters, evaluate each model's CV score.
-
The optimal hyperparameters are those of the model achieving the best CV score.
-
Suffers from the curse of dimensionality ⇒ the bigger the grid the longer it takes to find the solution.
-
-
Random Search
-
Bayesian Optimization
-
Genetic Algorithms
-
source
source
source
Support Vector Machines
Discriminative classifier formally defined by a separating hyperplane
-
Maximum Margin Hyperplane | Support Vectors
{xi, yi} where i = 1 . . . L, yi ∈ {-1, 1}, x ∈ ℝD
Kernel SVM
Mapping to a higher-dimensional space, applying the support vector algorithm & then projecting back to lower dimensional space resulting in a nonlinear separator
-
Linearly Separable with Hyperplane in 3D
-
The Gaussian or Radial Basis Function (RBF) Kernel
-
Sigmoid Kernel
-
Polynomial Kernel
φ(x1, x2) ⇒ (x1, x2, z)
↳ where:
↳ K = function applied to two vectors
↳ x = point in datasets
↳ l = landmark
↳ x = point in datasets
↳ l = landmark
K(X, Y) = tanh(γ ˙ XTY + r)
K(X, Y) = tanh(γ ˙ XTY + r)d, γ > 0
Naive Bayes Classification
Probabilistic classifier based on Bayes Theorem with an assumption of independence between predictors (aka, features or independent variables)
-
Bayes Theorem ⇒ The probability of an event given prior knowledge of related events that occurred earlier
K-Nearest Neighbors
An algorithm that predicts the label of a data point in both classification & regression. The algorithm stores all available cases & classifies new cases by a "majority vote" of its K-nearest neighbors
-
Euclidean Distance
Unsupervised Learning
"Looks for previously undetected patterns in a data set with no
pre-existing labels and with a minimum of human supervision"
"[P]resent examples without any hint, leaving it to the algorithm to
create a label. For instance, when we need to figure out how the groups inside
a customer database can be partitioned into similar segments based on their
characteristics and behaviors." WGU MSDA
-
K-Means Clustering
-
Within Cluster Sum of Squares (WCSS)| Quantifiable metric to evaluate how certain number of clusters performs compared to different number of clusters
-
Apriori Association
-
Support
-
Confidence
-
Lift → measuring the relevance of an associated rule & the improvement prediction
Unsupervised algorithm which solves clustering problems; follows simple/easy way to classify a dataset through a certain number of clusters
WCSS = Σ distance(Pi, C1)2 + Σ distance(Pi, C2)2 +Σ distance(Pi, C3)2
↳ where:
↳ distance = distance between each point inside cluster
↳ C = centroids, respectively
↳ C = centroids, respectively
Analyzes the association of specific preferences in customer transactions (movies watched, items purchased in convenience store - beer & pampers urban myth) to discover relationships and how items are associated with each other
Movie recommendation example:
↳ where M = specific Movie
Reinforcement Learning
"how software agents ought to take actions in an environment in order
to maximize the notion of cumulative reward"
"[P]resent examples without labels, as in unsupervised learning, but get
feedback from the environment as to whether label guessing is correct or not.
For instance, when we need software to act successfully in a competitive setting,
such as a videogame or the stock market, we can use reinforcement learning.
In this case, the software will then start acting in the setting and it will
learn directly from its errors until it finds a set of rules that ensure its
success." WGU MSDA
-
Upper Confidence Bound Algorithm | Deterministic Model
-
Advertising Model (requires update at every round)
Modern application of Multi-Armed Bandit Problem (reference slot machine distributions)
Step 1: Each round n considers two numbers for each ad i:
↳ Ni(n) → # of times the ad i selected up to round n
↳ Ri(n) → Σ of rewards of ad i up to round n
Step 2: From these two numbers we compute:
↳ Average reward of ad i up to round n with:
↳ Ri(n) → Σ of rewards of ad i up to round n
↳ Confidence interval [r̄i(n) - △i(n), r̄i(n) + △i(n)] at round n with:
Step 3: Select the ad i that has the maximum UCB r̄i(n) +
△i(n)
-
Thompson Sampling Algorithm | Probabilistic Model
-
Advertising Model (can accomodate delayed feedback & has better empirical evidence than UCB)
Constructs distributions of where we think the actual expected value might lie; an auxiliary mechanism to solve the problem
Step 1: Each round n considers two numbers for each ad i:
↳ Ni1(n) → # of times the ad i rewarded 1 up to round n
↳ Ni0(n) → # of times the ad i rewarded 0 up to round n
Step 2: For each ad i, we take a random draw from the distribution below:
θi(n) = β(Ni1(n) + 1, Ni0(n + 1))
↳ Ni0(n) → # of times the ad i rewarded 0 up to round n
θi(n) = β(Ni1(n) + 1, Ni0(n + 1))
Step 3: Select the ad i that has highest θi(n)
-
Random Forest Regression
-
Dimensionality Reduction
-
Gradient Boosting
Ensemble decision trees; a collection of decision trees (aka forest) to classify a new object based on attributes; each tree gives a classification & we say the tree "votes" for the class
Identifies highly significant variables when you have thousands
Ensemble of machine learning algorithms
Lovely Deep Learning
"[M]achine learning uses multiple layers of simple, adjustable computing
elements." (Russell, p. 26)
"Deep learning solves [the] central problem in representation learning
by introducing . . . simpler representations . . . [and] enables the computer
to build complex concepts out of simpler concepts . . . breaking the desired
complicated mapping into a series of nested simple mappings . . . called
"hidden [layers]" because their values are not given in the data." (Bengio, p. 5-6)
Artificial Neural Networks
↳ A computing system that consist of a number of simple but highly interconnected elements or nodes, called ‘neurons’, which are organized in layers which process information using dynamic state responses to external inputs, an extremely useful algorithm for finding patterns too complex to be manually extracted
-
Neuron Definition
-
Neuron Formula
-
Sigmoid Activation Function
-
Threshold Function
-
Rectifier Function
-
Hyperbolic Tangent Function (tanh)
A mathematical operation that takes its input, multiplies it by its weight & then passes the sum through an activation function
Y1 = activation(w1x1 + w2x2 + w3x3 + . . . + wmxm)
Σwixi
Σwixi
Σwixi
Σwixi
Convolutional Neural Networks
↳ A class of deep neural networks, most commonly applied to analyzing visual imagery. CNNs are regularized versions of multilayer perceptrons. Multilayer perceptrons usually mean fully connected networks, that is, each neuron in one layer is connected to all neurons in the next layer.
Natural Language Processing
↳ Starts with raw text in whatever format available, processes it, extracts relevant features and builds models to accomplish various NLP tasks
-
NLP Pipeline
-
Document-Term Matrix
Compute dot product (sum of the products of corresponding elements) to find similarities
a * b = Σ (a1b1 + a2b2 + a3b3 + . . . + anbn)
-
Cosine Similarity
Divide the product of two vectors by their magnitudes or Euclidean norms
-
TF-IDF Transform
Term frequency-inverse document frequency
tfidf(t, d, D) = tf(t, d) * idf(t, D)
↳ where:
tf(t, d) =
idf(t, D) = -
Stemming
Takes the root of a word removing conjugation to simplify & understand gist meaning (reducing final dimension )
Text Processing ⇒ Feature Extraction ⇒ Modeling
Lemmatization
Refers to doing things properly with the use of a vocabulary and morphological analysis of words, normally aiming to remove inflectional endings only and to return the base or dictionary form of a word, which is known as the lemma.
Mathematics
Etymology: The word "mathematics" comes from Ancient Greek máthēma (μάθημα), meaning "that which is learnt," "what one gets to know," hence also "study" and "science". Wikipedia
Intimate Linear Algebra
The study of linear equations & geometric transformations using matrices,
vectors spaces & determinants.
"Solving for unknowns within a system of linear equations." Mathematical Foundations of Machine
Learning
Fundamental Mathematical Objects
-
Scalars
A scalar is simply a single number, in contrast to the other mathematical objects studied in linear algebra. A scalar can be thought of a matrix with a single entry. (Goodfellow, pg. 29)
-
Vectors
A vector is an array of numbers. Vectors can be thought of matrices that contain only one column. (Goodfellow, pg. 30)
-
Matrix
A matrix is an a two dimensional array of numbers such that each element is identified by two indices instead of just one. (Goodfellow, pg. 30)
-
Transpose
"[T]he mirror image of a matrix across a diagonal line. The transpose of a vector is therefore a matrix with only one row" (Goodfellow, pg. 31).
-
Matrix product
Perhaps the most important operation of matrices is their multiplication. The matrix product of matrices A and B is a third matrix C.
Σ
-
-
Tensor
"In some cases we will need an array with more than two axes. . . . [A]n array of numbers arranged on a regular grid with a variable number of axes . . ." (Goodfellow, pg. 31)
In an n-dimensional space a tensor of rank n is a mathematical object that has n indices, mn components and obeys certain transformation rules. -
Matrix Notation
-
Sparse Matrix
In numerical analysis and scientific computing, a sparse matrix or sparse array is a matrix in which most of the elements are zero.
Linear Regression
-
Matrix-Vector Multiplication Function
↳ where:
Determinants
↳ The volume scaling factor of the linear transformation described by the matrix
-
Square Matrices
-
Determinant Equation 2x2 Matrix
-
Trace of Matrix
Equal to the sum of the values along the main diagonal
-
Geometrical Aspects of Linear Algebra
↳ Mathematics to used see through to the governing dynamics of the physical universe
Orthonormal Bases
-
Orthogonality
Every vector in set is orthogonal to every other vector in set; as perpendicular is to two-dimensional space (vectors at 90° angle), orthogonal is to three- or n-dimensional space.
-
Normality
Every vector has been normalized; every vector has a length of 1.
-
Projection onto an Orthonormal Basis
Using an orthonormal subspace drastically simplifies projection equation from:
↓
-
Gram-Schmidt Process
Converts non-orthonormal set into an orthonormal set
Eigenvalues & Eigenvectors
Literally "special" or "self" values/vectors that correspond to a matrix or linear transformation; a way to diagonalize a problem, adjusting specific parts without disturbing others
-
Eigenvector Transformation ( Brilliant 3Blue1Brown visualization)
↳ algebraically:
-
Eigenspace (Eλ)
↳ where:
Fast Fourier Transformation
"A fast Fourier transform is an algorithm that computes the discrete Fourier transform of a sequence, or its inverse. Fourier analysis converts a signal from its original domain to a representation in the frequency domain and vice versa." Wikipedia
Salient Statistics & Probabilities
Statistics is the art of making numerical conjectures about puzzling questions.
↳ Is statistics a field of mathematics? Some say it is not mathematics but the science of data. Whatever you decide, you must embrace it, my Dear Friends.
Terminology
-
Index: a descriptive statistic made up of other descriptive statistics that consolidates lots of information into a single number
Probability
Generalizing logic to situations with uncertain outcomes & measurements,
& incomplete theories; the possible outcomes of events.
"The formalization of probability, combined with the availability of data,
led to the emergence of statistics as a field."
Artificial Intelligence: A Modern Approach, pg 8
-
Basic Formulae
-
Probability of an Event
-
Complement of an Event
-
Union(∪, Or) & Intersection(∩, And)
-
Permutations & Combinations
-
The Combinatorial Explosion
-
-
Bayes' Theorem
Tells the probability of an event given prior knowledge of related events that occurred earlier
-
Bayesian Analysis: Probability of B given A
↳ where:
A = cause event
B = effect event
P(A|B) = probability of cause A given effect B is true
P(B|A) = probability of effect B given cause A is true
P(A), P(B) = independent probabilities of effect A & cause B
-
-
Random Walk
"A process for determining the probable location of a point subject to random motions, given the probabilities (the same at each step) of moving some distance in some direction. Random walks are an example of Markov processes, in which future behaviour is independent of past history."
-
Drunkard's Walk
"A typical example is the drunkard’s walk, in which a point beginning at the origin of the Euclidean plane moves a distance of one unit for each unit of time, the direction of motion, however, being random at each step. The problem is to find, after some fixed time, the probability distribution function of the distance of the point from the origin. Many economists believe that stock market fluctuations, at least over the short run, are random walks." This is observed in Brownian Motion.
P(A ∪ B) = P(A) + P(B) - P(A ∩ B)
Descriptive Statistics
"Descriptive statistics are brief descriptive coefficients that summarize a given data set, which can be either a representation of the entire or a sample of a population. Descriptive statistics are broken down into measures of central tendency and measures of variability (spread)." Investopedia
Used to describe data; univariate analysis on a single variable or multivariate analysis when looking at two or more variables in the dataset
-
Moments of Statistics
-
Location
-
Variability
-
Skewness
-
Kurtosis
-
-
Estimates of Location (Measures of Central Tendency)
-
Mean
-
Trimmed Mean
-
Weighted Mean
-
-
Estimates of Variability
Second dimension (after estimate of location) in summarizing a feature, aka dispersion, measures whether data are tightly packed or spread out.
-
Mean Absolute Deviation
-
Variance
-
Standard Deviation
"Sort of" the average distance from the mean.
-
Median Absolute Deviation (MAD)
* A robust estimate of variability as opposed to variance & standard deviation.
-
-
Data Distribution
-
Empirical Rule or Three Sigma Rule
Symmetrically distributed data follows a pattern whereby most data points fall within three standard deviations of the mean.
-
Relative Frequency
The proportion of times a value occurs in a dataset.
-
Z-Scores
A measure of the number of standard deviations a particular data point is from the mean.
-
Percentile Rank
-
Percentile: Precise Definition
Take any value between the order statistics (sorted or ranked data) x(j) & x(j + 1) where j satisfies:
The percentile is the weighted average:
for some weight between 0 & 1.
-
N-Quantiles
-
Index i for k-th cut point
-
-
-
Binary & Categorical Data
Simple proportions or percentages tell the story of the data
-
Expected Value (EV)
When the categories can be associated with a numeric value, this gives an average value based on a category's probability of occurrence. A form of weighted mean in which the weigths are probabilities, the EV adds the ideas of future expectations & probability weights, often based on subjective judgements.
-
Multiply each outcome by its probability of occurrence.
-
Sum theses values.
EV = (weight as %)(component value) + (weight as %)(component value) + (weight as %)(component value)
-
-
Probability
Probability is essentially a ratio. The ratio of a particular event or outcome versus all the possible outcomes.
Total probability of sample space: the sum of probabilities of all possible outcomes must add up to 100%.-
Objective Probability
"Objective probability refers to the chances or the odds that an event will occur based on the analysis of concrete measures rather than hunches or guesswork. ... The probability estimate is computed using mathematical equations that manipulate the data to determine the likelihood of an independent event occurring." Investopedia
-
Classical
All possible outcomes are known & equally ikely; everything is fair & equal, eg, a coin toss or roll of dice.
-
Empirical
AKA, relative frequency or experimental probability is the ratio of the # of outcomes for a specific event to the total number of subsequent trials. Based on observed data from past events, eg, odds of favorite ball team winning.
-
-
Subjective Probability
"a type of probability derived from an individual's personal judgment or own experience about whether a specific outcome is likely to occur. It contains no formal calculations and only reflects the subject's opinions and past experience." Investopedia
-
-
Correlation
A measurement of the extent to which numeric variables are associated with one another.
-
Pearson's Correlation Coefficient (r)
A measure of linear correlation between two sets of data; will always lie between +1 (perfect positive correlation) & -1 (perfect negative correlation).
-
Correlation Matrix
A table where the variables are shown on both rows & columns, & the cell values are the correlation between the variables.
v1 v2 v3 v1 1 0 0 v2 0 1 0 v3 0 0 1
-
-
Inferential Statistics
Putting foundational statistics to use with samplig to find meaningful statistics that will inform us about a population.
"Scholars interested in human society . . . grasped these ideas and found to their surprise that the variation in human characteristics and behavior often displays the same pattern as the error in measurement . . ." (regarding the
application of the standard normal distribution to social science in the early 19th century)
- Leonardo Mlodinow, The Drunkard's Walk: How Randomness Rules Our Lives
-
Simple Random Sample
The most dependable data comes from simple random samples.
-
Each individual has the same probability of being chosen at any stage.
-
Each subset of k individuals has the same probability of being chosen as any other subset containing k individuals.
Must exhibit two key characteristics:
-
Unbiased sample
-
Independent data points
-
-
Law of Large Numbers
When performing experiments, the average of the results from large numbers of trials should be close to the expected value & will tend to become closer to the expected valueas more trials are performed. Experimental probability will eventually lead to theoretical probability. As a sample size grows, its mean gets closer to the average of the whole population.
-
Theoretical Probability
Classical probability is the likelihood that an event will occur if we could run trials of an experiment an infinite number of times.
-
-
Law of Error
The equation of the normal probability curve to which the accidental errors associated with an extended series of observations tend to conform.
-
Central Limit Theorem
If you have a population with mean μ and standard deviation σ and take sufficiently large random samples from the population with replacement , then the distribution of the sample means will be approximately normally distributed.
-
Parametric vs. Non-Parametric
"Parametric tests assume that your data follows a particular known distribution, usually the Normal Distribution . . . Those distributions have been studied a lot . . .
The mean, median & standard deviation are examples of parameters & testing the differences in the parameters of distribution-A vs. Distribution-B is exactly what parametric tests do. They are useful & powerful because as long as your own data approximates the known distribution you can learn a lot about your own data by inferring the same conclusions you would with the known distribution.
Non-parametric tests don't make any assumption about what known distribution your data might follow. They don't assume the shape of your data is 'Normal' . . . and therefore are not able to infer powerful conclusions of those known distributions. Mostly N on-Parametric tests rank data in order and compare. Median tests work like this (e.g.Moods Median test). The Median is a parameter, but the test is not making assumptions about what distribution your data follows, thus it's a non-Parametric test." Reddit ELI5 -
Standard Error
A single metric that sums up the variability in the sampling distribution for a statistic.
↳ where:
-
Square Root of n Rule
To reduce the standard error by a factor of 2, the sample size must be increased by a factor of 4.
-
Bootstrap Algorithm
A powerful tool for assessing the variability of a sample statistic. To draw additional samples, with replacement, from the sample itself & recalculate the statistic or model for each resample.
- Draw a sample value, record it & then replace it.
- Repeat n times.
- Record the mean of the n resampled values.
- Repeat steps 1-3 R times.
-
Use the R results to:
- Calculate their standard deviation (this estimates sample mean standard error).
- Produce a histogram or boxplot.
- Find a confidence interval.
-
Probability Distribution vs. Probability Density Function
A probability distribution is a list of outcomes and their associated probabilities. A function that represents a discrete probability distribution is called a probability mass function. A function that represents a continuous probability distribution is called a probability density function.
-
F-Distribution
The F-statistic measures the extent to which differences among group means are greater than we might expect under normal random variation. Also called residual variability, this comparison is termed analysis of variance.
-
Statistical Significance Tests & ANOVA
Is there a significant difference among groups tested? How significant is that difference? Think Alpha level.
-
T-tests measure one or two groups.
-
T-tests tell you which group is different.
-
One-sample known as a student t-test & will determine significance against a known population mean.
-
Two sample T-tests (independent samples) will determine significance between two groups of data.
"A test to determine whether the average of two samples is different when either the sample set is too small (that is, fewer than 30 data points per sample), or if the population standard deviation is unknown. The two samples are also generally drawn from distributions assumed to be normal." (Malik, p. 39). -
A paired T-test (dependent samples) will determine signifcance for the same group at different times (pre- & post-test).
-
Calculating T-test require at least three values:
-
the group means or mean difference
-
the standard deviation of each group
-
the # of data values of each group
-
for one-sample T-test, the hypothesized or population mean
-
-
A two sample Z-test is a "test to determine whether the averages of the two samples are different. This test assumes that both samples are drawn from a normal distribution with a known population standard deviation" (Malik, p. 39).
-
ANOVA measures more than two groups.
-
Both are parametric & means tests.
-
Both require normal distributions, homogeneity of variance & random sampling.
-
Both measure a ratio or interval level (continuous) dependent variable.
-
If you have a significant difference among several groups, post-hoc testing will be necessary to provide further investigation.
-
-
Difference Between r & R2
-
The value r is the correlation between observed values of Y & predicted values of Ŷ. In essence, it is the relationship between two variables, say weight & height. The positive & negative values express that relationship as proportional or inversely proportional. So, r deals with the relationship of two variables.
-
R2 is the coefficient of determination. It is the percentage of variation in the response variable that is explained by the linear model - how strongly multiple variables are correlated with the target variable. It is r times the r value.
-
-
Poisson Distributions
Measuring a count of events over some interval of time/space. In many applications, the event rate, λ, is known or can be estimated from prior data.
-
Weibull Distribution
An extension of the exponential distribution in which the event rate is allowed to change, as specified by a shape parameter, β.
-
Gaussian Distribution Formulas
-
T Distribution
Aka the Student's t-distribution, is a type of probability distribution that is similar to the normal distribution with its bell shape but has heavier tails. T distributions have a greater chance for extreme values than normal distributions, hence the fatter tails.
-
Binomial Distribution Formulas
-
Mean
-
Standard Deviation
-
Variance
-
Probability Density Function
-
Sample Distribution of the Sample Proportion
-
Mean & Standard Error
-
Mean Squared Error & Root Mean Squared Error
-
Confidence Interval
Simply, a confidence interval provides a level of confidence for a given interval. Or, more specifically, a range of values so defined that there is a specified probability that the value of a parameter lies within it.
-
CI for a Population Mean
-
CI for Population Proportion
-
Solved for Sample Size (n)
-
Margin of Error (ME)
"A margin of error tells you how many percentage points your results will differ from the real population value. For example, a 95% confidence interval with a 4 percent margin of error means that your statistic will be within 4 percentage points of the real population value 95% of the time." StatisticsHowTo
-
Chi-Square Distribution
The statistic that measures the extent to which results depart from the null expectation of independence. It is distribution-free & non- parametric. Must be used when dealing with categorical dependent variable, for example binary, "yes/no", target variable.
-
Chi-Square Tests(χ2)
"A test to determine whether the distribution of data points to categories is different than what would be expected due to chance. This is the primary test for determining whether the proportions in tests, such as those in an A/B test, are beyond what would be expected from chance" (Malik, p. 39).
Assumptions
-
Data in cells should be frequencies or counts of cases.
-
Levels (or categories) of the variables are mutually exclusive.
-
Each subject may contribute to one & only one cell.
-
Study groups must be independent.
-
Two variables, both are measured as categories, usuallys at the nominal level.
-
Values in cells should be five or more.
Features
-
A hypothesis test comparing two or more proportions, Ho: P1 = P2
-
Random samples are required.
-
Observations are independent.
-
Uses χ2 table to show the critical values of the χ2 distribution.
I. Goodness of Fit Test:
Tests if a categorical variable follows a hypothesized distribution.
-
Simple random sampling
-
Categorical variables
-
Expected frequency count from previous samples, ex. percentage by category
-
Degrees of freedom is k - 1
-
Ho: the population frequencies = expected frequencies values.
Ha: the null hypothesis is false. -
Test statistic is defined:
II. Test for Independence:
Looks for significant difference between two categorical variables.
-
Simple random sampling
-
Categorical variables
-
Expected frequency count for each cell of the table is at least five
-
Degrees of freedom:
↳ where:
r = # of levels (rows) for one categorical variable
c = # of levels (columns) for the other -
Expected Frequencies:
-
Test statistic is defined:
III. Test for Homogeneity:
Tests for difference in proportion between several groups.
-
An estimator (of a procedure for estimating an unobserved quantity) measures the average of the squares of the errors—that is, the average squared difference between the estimated values and the actual value
or
↳ where:
a = lower limit of confidence interval
b = upper limit of confidence interval
z* = critical value ⇒ z-score
α = (1 - confidence level) ⇒ signicance level
↳ where:
p̂ = sample proportion
Statistical Significance Testing
-
Test Statistic: proportion, average, difference between groups or a distribution
-
Hypothesis Test Logic: "Given the human tendency to react to unusual but random behavior and interpret it as something meaningful and real, in our experiements we will require proof that the difference between groups is more extreme than what chance might reasonably produce."Practical Statistics for Data Scientists (p. 94)
-
Null Hypothesis(Ho): a baseline assumption that the treatments in an experment are equivalent & the results observed are a product of chance
-
Alternative Hypothesis(Ha or H1): the results observed in an experiment cannot be explained by chance
-
Significance Level: the value of the test statistic needs to take before it is decided that the Null Hypothesis cannot explain the difference
-
Statistically Significant: "A result of an experiment is said to have statistical significance, or be statistically significant, if it is likely not caused by chance for a given statistical significance level. ... It also means that there is a 5% chance that you could be wrong." Optipedia
-
p-value
Given a chance model that embodies the null hypothesis, the p-value is the probability (frequency) of obtaining results as unusual or extreme as the observed results.
-
Alpha
The probability threshold of "unusualness" that chance results must surpass for actual outcomes to be deemed statistically significant.
-
Type I Error
Mistakenly concluding an effect is real (when it is due to chance).
-
Type II Error
Mistakenly concluding an effect is due to chance (when it is real).
-
Degrees of Freedom
The number of values free to vary & affects the shape of the distribution; the name given the n - 1 denominator seen in the calculation for variance & standard deviation. When you use a sample to estimate the variance for a population, you will end up with an estimate that is slightly biased downward if you use the n in the denominator. If you use n - 1 in the denominator, the estimate will be free of bias.
The concept of degrees of freedom lies behind the factoring of categorical variables into n - 1 indicator or dummy variables when doing a regression (to avoid multicollinearity).
-
-
ANOVA (Analysis of Variance)
The statistical procedure that tests for a statistically significant difference among multiple groups.
-
Pairwise Comparison
A hypothesis test (e.g., of means) between two groups among multiple groups. The more such pairwise comparisons we make, the greater the potential for being fooled by random chance.
-
Omnibus Test
A single hypothesis test of the overall variance among multiple group means.
-
Decomposition of Variance
Separation of components contributing to an individual value (e.g., from the overall average, from a treatment mean, & from residual error).
-
F-statistic
A standardized statistic that measures the extent to which differences among group means exceed what might be expected in a chance model.
-
SS
"Sum of squares," referring to deviations from some average value.
-
-
p-value
Given a chance model that embodies the null hypothesis, the p-value is the probability (frequency) of obtaining results as unusual or extreme as the observed results.
-
Alpha
The probability threshold of "unusualness" that chance results must surpass for actual outcomes to be deemed statistically significant.
-
Type I Error
Mistakenly concluding an effect is real (when it is due to chance).
-
Type II Error
Mistakenly concluding an effect is due to chance (when it is real).
-
Degrees of Freedom
The number of values free to vary & affects the shape of the distribution; the name given the n - 1 denominator seen in the calculation for variance & standard deviation. When you use a sample to estimate the variance for a population, you will end up with an estimate that is slightly biased downward if you use the n in the denominator. If you use n - 1 in the denominator, the estimate will be free of bias.
The concept of degrees of freedom lies behind the factoring of categorical variables into n - 1 indicator or dummy variables when doing a regression (to avoid multicollinearity).
-
ANOVA (Analysis of Variance)
The statistical procedure that tests for a statistically significant difference among multiple groups.
-
Pairwise Comparison
A hypothesis test (e.g., of means) between two groups among multiple groups. The more such pairwise comparisons we make, the greater the potential for being fooled by random chance.
-
Omnibus Test
A single hypothesis test of the overall variance among multiple group means.
-
Decomposition of Variance
Separation of components contributing to an individual value (e.g., from the overall average, from a treatment mean, & from residual error).
-
F-statistic
A standardized statistic that measures the extent to which differences among group means exceed what might be expected in a chance model.
-
SS
"Sum of squares," referring to deviations from some average value.
-
-
Common Significance Tests
↳ Using the population mean (μ):
-
Z-Test | When σ is known
-
T-Test | When σ is unknown | large sample > 30
-
T-Test | When σ is unknown | small sample < 30 | assume normal distribution
↳ Using the population proportion (p):
-
Pearson's Chi-Squared Test | Expected value of population proportion (p̂) known
-
Regression
↳ So . . . why is it called "Regression", anyway?
-
Regression Analysis
Process used to turn a set of disconnected data points into an equation that models the whole set; the process of aproximating a trend with a mathematical function
-
Trend or Regression Line, Approximating Curve, Line of Best Fit, Least Squares Line
-
Slope
-
Y-intercept
-
Correlation Coefficient
or
-
Pearson Correlation Coefficient
Method for quantifying linear correlation, represented by r is a number ranging from -1 to 1 & indicating how well a scatter plot fits a linear trend
-
Standard Deviation
-
Residual or Error
-
Sum of Residuals
-
Coefficient of Determination
Gives a percentage of how much better fit the line of regression is than the ȳ
-
Root Mean Squared Error (RMSE) or Standard Deviation of the Residuals
The smaller the RMSE, the better fit the line of regression
-
Chi-Square Tests (χ2)
Pearson's Chi-Square Test is used to ask whether the differences you observe between different groups are real or imagined.
The larger the the χ2-value, the more likely the two variables affect each other -
Degrees of Freedom (df)
The number of values you would need in your data in order to be able to know all the other values
-
Dynamic Calculus
The mathematics of curves, motion and change, calculus is basically very advanced algebra (finding rates & slopes) & geometry (addition to infinity & finding area).
Three Central Problems of Calculus
-
Forward Problem: given a curve, find its slope everywhere
-
Backward Problem: given the slope everywhere, find the curve
-
Area Problem: given the curve, find the area under it
Fundamental Theorem of Calculus (FTC)
Shows the relationship between differentiation & integration. If a function is integrated & then differentiated, it is back to the original function. Integration & differentiation are inverse to each other.
-
Part 1
-
Differentiation
-
Differentiation
The derivative function tells how fast & where the function is increasing or decreasing.
-
Derivatives
Finding the slope of a function at a specific point.
-
f′(x) or
↳ where:
-
Integration
The integral of a function models the area under the graph of a function.
-
Antiderivatives & Indefinite Integrals
Find the area under the curve everywhere, over the entire domain of the function; the interval is unbounded & there are no limits on the interval.
-
Integral for Basic Power Functions
-
-
Definite Integrals
-
The Interval
Find the area under the curve over a specific interval, at the limits of integration.
-
-
Riemann Sums
Way to geometrically estimate the area under a curve: divide the area into many thin rectangles, find the subsequent areas & then sum those areas
-
Summation Notation
-
Expanding Series
-
Riemann Sum Formula
Use midpoints, left or right endpoints of finite # of rectangles to estimate the area under the curve
↳ expanded:
↳ where:
-
-
Midpoint Rule
Other Approximation Methods
-
Limit Process to Find Area
Step 1: define width of subinterval or Δx
↳
Step 2: define xi as # of subintervals
↳
Step 3: apply summation notation for i, i2 & i3 as series
↳
↳
↳ -
Trapezoidal Rule
Approximating area under curve may be more accurate because trapezoids get closer to the actual curve than rectangles
-
Simpson's Rule
The value of n must be even
Error Bounds
Largest possible value of error of approximation; level of reliability
-
Midpoint Rule (EM)
-
Trapezoidal Rule (ET)
Integration by Parts Formula
Using u substitution to simplify our integral to make it easier to evalutate.
Computer Science Mathematics
Absolute Value Inequalities
-
Absolute Value of a Function
-
Less Than a
Closer to zero than a
-
Greater Than a
Further away from zero than a
-
Scientific Notation
Any number can be written in scientific notation. It involves shifting the decimal place to the left (positive) or right (negative) until the result is a number with only one place before the decimal point & then multiplying by 10 raised to the number of places shifted.
-
Notation Process Result
-
A decimal number less than 10 and greater than 1 multiplied by,
-
10 raised to a specific whole number
-
-
Example:
NP Complete Problem
"We call these problems "nondeterministic polynomial" or NP, because you
can't give someone a pre-determined set of steps to solve it (unless that
someone is a perfect guesser!), but if someone does happen to solve it,
they would only need a polynomial number of steps. . . .
[W]e can find the answer to any NP problem by solving a related
problem in this group. The problems in this group are called "NP-complete"
(because solving one of them can solve the complete group of NP problems).
If we ever found a fast (i.e. polynomial) way to solve any NP-complete
problem, we could find fast ways to solve every NP problem. Then we wouldn't
have to talk about NP any more, because they would all just be P (polynomial)
problems. That's why we call the problem "P=NP". . . .
[M]athematicians think that NP-complete problems are not P,
because so many people have spent so much time thinking about it that if
they were, somebody would have found out how by now (because it's usually
easier to find a way to do something than to prove that there is no way)."
Reddit ELI5
-
P: The set of all problems that can be solved in polynomial time (polynomial in relation to the input) by a deterministic Turing machine.
-
NP: The set of all problems that can be solved in polynomial time if you have a non-deterministic Turing machine. That is, if you have a magical computer that can perform both actions at a decision point simultaneously. However, given a proposed solution to a problem in NP, that solution can be verified in polynomial time by a normal, deterministic Turing machine.
-
NP-hard: The set of all problems that any problem in NP can be reduced to in polynomial time.
-
NP-complete: The set of problems that any problem in NP can be reduced to in polynomial time, whose solutions can still be verified in polynomial time. This is the subset of NP-hard that overlaps NP. Generally-speaking, the set of NP-complete problems is a kind of "upper bound" on the complexity of NP problems. Every NP problem can be solved by an NP-complete problem, and the solution can be verified in polynomial time.
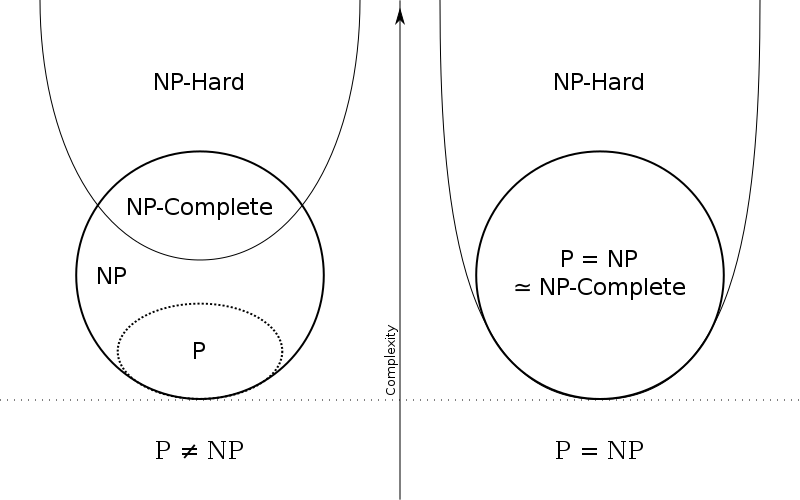
Marvelous Logarithms
Logarithms were the supercomputers their era. See the Description of the Marvelous Canon of Logarithms by John Napier
-
Rule of Logs: the log of a product is the sum of the logs
Logarithms undo the actions of exponential functions. Logarithms & exponentials are inverse functions -
Inverse of an Exponential Function
y = ax ⇒ x = ay
100 = 102 ⇒ log10 of 100 = 2 -
Logarithmic Function
""[S]imply an exponential function with the x & y axes swtitched. In other words, the up-and-down direction on an exponential graph corresponds to the right-and-left direction on a logarithmic graph, & the right-and-left direction on an exponential graph corresponds to the up-and-down direction on a logarithmic graph." (Ryan, p. 59)
-
The relationship of exponetial to logarithmic
(the exponential function) x = ay ⇒ loga of x = y (the logarithmic function)
-
The Binary Logarithm
Log2 n is the power to which the number 2 must be raised to obtain the value n.
For any real number x:
Cordially Discrete Mathematics
Branch of mathematics dealing with discrete (distinct & disconnected) or finite sets of elements
rather than continuous or infinite sets of elements. The terms discrete & continuous are analogous to the computer science terms digital & analog.
* Brilliant course from Shawn Grooms at freeCodeCamp: Math for Programmers
-
Set of Natural Numbers
ℕ = {1, 2, 3, . . .} ⇒ The set of Natural Numbers (Cardinal or Counting Numbers) include all positive, non-zero integers.
-
Set of Integers
ℤ = {. . . , -1, 0, 1, . . .}
-
Set of Rational Numbers
⇒ The set of Rational Numbers include ratios of two integers where the denominator is non-zero.
-
Binary Operators for Sets
-
For Sets:
A = {x, y, z}
B = {c, x, y} -
Union
⇒ A union B equals the set containing elements p, such that p is an element of A or p is an element of B.
-
Intersection
⇒ A intersection B equals the set containing elements p, such that p is an element of A and p is an element of B.
-
-
Logic
Logic is a systematic way of thinking that allows us to deduce new information from old information & to parse the meaning of sentences.
Logic ⇒ Mathematics ⇒ Algorithms ⇒ Code
-
The Universal Set
The Universe is the maximum boundary of extant sets; it is the largest set; everything outside the Universal Set does not exist.
If the Universel Set is not defined, we assume it to be the set of Real Numbers (ℝ). -
Associativity
We can regroup the sets we are talking about - it does not matter where we put our parentheses.
-
Commutativity
We may switch which side our sets are on relative to the operator.
-
Distributivity
A set & its operation will be shared over another set & operation.
-
Propositions
A proposition is a declarative statement with a verifiable truth value; usually denoted with a lower-case letter.
p = Cats are smart, furry animals. > ^+^ <
q = Cats have pet humans. -
Composite Propositions
A proposition is a declarative statement with a verifiable truth value; including two or more subpropositions.
-
Conjuction (AND, "∧")
p∧q = "Cats are smart, furry animals AND cats have pet humans."
-
Disjuction (OR, "∨")
p∨q = "Cats are smart, furry animals OR cats have pet humans."
-
-
Truth Tables
Easy visualization of why a statement is true or false
p q p∧q p∨q T T T∧T = T T∨T = T T F T∧F = F T∨F = T F T F∧T = F F∨T = T F F F∧F = F F∨F = F -
Algebraic Laws of Logic
-
Idempotence Law
Denoting an element of a set which is unchanged in value when multiplied or otherwise operated on by itself.
P ≡ P∨P ≡ P∧P
-
Identity Law
The conjunction of any proposition P with an arbitrary tautology T will always have the same truth value as P. It will be logically equivalent to P
The disjunction of any proposition P with an arbitrary tautology T will always be true. It will itsefl be a tautology.P ≡ P ∨ False ≡ P ∧ True
True ≡ P ∨ True
False ≡ P ∧ False -
Complements Law
Where a propostion P is True:
P∨¬P ≡ True True ≡ ¬ False
P∧¬P ≡ False False ≡ ¬ True -
Involution Law
If we have a proposition and we feed it through a function twice we'll end up in the same spot.
P 𠪪 P
-
Commutative Law
Relating to number operations of addition & multiplication, any finite sum is unaltered by reordering its terms or factors.
p ∨ q ≡ q ∨ p
p ∧ q ≡ q ∧ p -
Associative Law
(p ∨ q) ∨ r ≡ p ∨ (q ∨ r)
(p ∧ q) ∧ r ≡ p ∧ (q ∧ r) -
Binary Operation
A calculation that combines two elements (called operands) to produce another element.
-
-
Logical Quantifiers
-
Propositional Function, p(x)
A statement expressed in a form that would take on a value of true or false were it not for the appearance within it of a variable x (or of several variables), which leaves the statement undetermined as long as no definite values are specified for the variables.
Encyclopedia Britannica -
Universal Quantifier, ∀
Literally "for every" or "for all"
Shorthand:
-
Existential Quantifier, ∃
Literally "there exists (at least one)"
-
-
Tautologies
Propositions that are always true.
-
Law of Excluded Middle
P∨¬P
"P OR not P"
-
Law of Contradiction
¬(P∧¬P)
"The negation of P AND not P"
-
Modus Tollens or "Denying the Consequent"
[(P ⇒ q) ∧ ¬q] ⇒ ¬P
"P implies q, AND not q, implies not P"
-
-
Proofs Terminology
-
Theorem
A mathematical statement that is true & can be (and has been) verified as true.
-
Proof
A proof of a theorem is a written verification that shows that the theorem is definitely and unequivocally true.
-
Definition
An exact, unambiguous explanation of the meaning of a mathematical word or phrase.
-
Proposition
A statement that is true and verifiable but not as significant as a theorem.
-
Lemma
A theorem whose main purpose is to help prove another theorem.
-
Corollary
A result that is an immediate consequence of a theorem or proposition.
-
Nimble Number Theory
The study of the numbers & their properties.
The Integers
-
The Fundamental Theorem of Arithmetic
Every positive integer can be written uniquely as the product of primes.
Constructs of the Universe
Mind-expanding & ancient wisdom from A Beginner's Guide to Constructing the Universe - Michael S. Schneider
The Monad | One
"The ancient philosophers conceived that the Monad breathes in the void and creates all subsequent numbers"
-
"Unity is all there really is, but polarity is required for any creation, so One casts its own shadow and pretends to be Two to generate the single digits:"
1 x 1 = 1
11 x 11 = 121
111 x 111 = 12321
1111 x 1111 = 1234321
11111 x 11111 = 123454321
111111 x 111111 = 12345654321
1111111 x 1111111 = 1234567654321
11111111 x 11111111 = 123456787654321
111111111 x 111111111 = 12345678987654321 -
Pascal's Triangle
Build the triangle with 1 at the top, continue placing numbers below in a triangular pattern. Each number below is the sum of the two numbers balanced above it.
Horizontal Sums ⇒ Powers of 21 = 1 = 20
1 1 = 2 = 21
1 2 1 = 4 = 22
1 3 3 1 = 8 = 23
1 4 6 4 1 = 16 = 24
1 5 10 10 5 1 = 32 = 25
1 6 15 20 15 6 1 = 64 = 26
1 7 21 35 35 21 7 1 = 128 = 27
1 8 28 56 70 56 28 8 1 = 256 = 28
1 9 36 84 126 126 84 36 9 1 = 512 = 29-
Diagonals
→ Ones
→ Counting Numbers
→ Triangular Numbers
→ Tetrahedral Numbers
→ Pentatope Numbers
-
The Dyad | Two
-
"The simplest arithmetic properties of any number reveal its deepest nature. Two is the balance or door linking the One with the Many."
1 + 1 > 1 x 1 → the Unique
2 + 2 = 2 x 2 → the Door
3 + 3 < 3 x 3 ↘
4 + 4 < 4 x 4 → the Many
5 + 5 < 5 x 5 ↗
The Triad | Three
The unity of the circle manifests as a trinity: center or point, radius or line & circumference.
-
The only number of the infinitely many to equal the sum of all terms below it.
3 = 2 + 1
-
The only number whose sum with those below equal their product.
1 + 2 + 3 = 3 x 2 x 1
The Tetrad | Four
Three points define a flat surface, but it takes a fourth to define depth, progress to three dimensions and express geometry as volume.
-
Using four 4s, create numbers 0 - 9 using mathematical operators Numberphile demonstration:
4 - 4 + 4 - 4 = 0
(4 ÷ 4) + 4 - 4 = 1
4 - (4 + 4) ÷ 4 = 2
(4 × 4 - 4) ÷ 4 = 3
4 + 4 × (4 - 4) = 4
(4 × 4 + 4) ÷ 4 = 5
(4 + 4) ÷ 4 + 4 = 6
4 + 4 - 4 ÷ 4 = 7
4 ÷ 4 × 4 + 4 = 8
4 ÷ 4 + 4 + 4 = 9
. . .
4 ? 4 ? 4 ? 4 = ∞
The Pentad | Five
Pentagonal symmetry is the supreme symbol of life.
-
The principle of ongoing growth-from-within is the esssence of the Pentad's principle of regeneration & is visible in the Fibonacci Sequence
0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610 . . .
The Hexad | Six
The Hexad is sometimes symbolized by the "Pythagorean triangle" or "3-4-5 right triangle" made by the ancient method using a twelve-knotted rope. It displays the sequence from one to six (1 - 6): one right angle (1), two unequal angles (2), sides of three (3), four (4), and five (5), and closing an area of six square units (6).
-
Multiples of six & the duodecimal frame are used for the structure, function & order of space-time
-
Structure
12 inches = 1 foot
36 inches = 1 yard
360 degrees = measure of a circle
60 minutes = 1 degree of arc
60 seconds = 1 minute of arc -
Function
12 = 1 dozen
12 dozen = 1 gross -
Order
60 seconds = 1 minute
60 minutes = 1 hour
24 hours = 1 day
30 days = 1 month
12 months = 1 year
-
The Heptad | Seven
Seven is perhaps the most venerated number of the Dekad, the number par excellence in the ancient world
-
Only Seven Numbers Exist
The ancient philosophers did not consider 1, 2 or 10 to be actual numbers but rather their source & result. So, the Dekad contains only 7 numbers: 3, 4, 5, 6, 7, 8 & 9.
-
A Link & a Chasm
1 × 2 × 3 × 4 × 5 × 6 × 7 = 5,040 = 7 × 8 × 9 × 10
The Octad | Eight
Periodic Renewal & the doubling number
-
Triple doubling & the beginning of exponetial growth
-
Curious Mathematical Relationship of Septad & Octad
Calculate 1 divide by 49 (=7×7)
The answer is an endless decimal built on the process of doubling = 0.020408163264128256. . .
The Ennead | Nine
Composed of a trinity of trinities, the number nine represents the principles of the sacred Triad taken to their utmost expression.
The ancient Greeks called nine "the horizon," as it lies at the edge of the numerical shore before the boundless ocean of numbers that repeat in endless cycles the principles of the first nine digits.
-
Multiplying by nine reveals a mirror symmetry among the numbers.
When any number is multipled by nine the resulting digits always add to nine.1 × 9 = 09 90 = 9 × 10
2 × 9 = 18 81 = 9 × 9
3 × 9 = 27 72 = 9 × 8
4 × 9 = 36 63 = 9 × 7
5 × 9 = 45 54 = 9 × 6
The Decad | Ten
The Decad represents the power to generate numbers beyond itself, toward the infinite. Multiplying any number by ten does not change its essential nature but only acts to expand its power.
-
The Tetraktys: an equilateral cosmological model of completeness of ten points unfolding in four levels.
10 = 1 + 2 + 3 + 4
⊙ ⊙ ⊙ ⊙
⊙ ⊙ ⊙ ⊙ ⊙ ⊙
⊙ ⊙ ⊙ ⊙ ⊙ ⊙
⊙ ⊙ ⊙ ⊙
1 3 6 10
Positively Brilliant References
-
Koshy, T. (2003). Discrete Mathematics & Its Applications. Academic Press.
-
Bengio, Y., Courville, A., & Goodfellow, I. (2016). Deep Learning. MIT Press.
-
Malik, U. (2019). SQL for Data Analytics. Packt Publishing.
-
Massaron, L. (2016). Regression Analysis with Python. Packt Publishing.
-
Russell, S. & Norvig, P. (2021). Artificial Intelligence: A Modern Approach. Pearson.
-
Ryan, M. (2016). Calculus for Dummies. For Dummies.
-
Schneider, M. (1994). A Beginner's Guide to Constructing the Universe: The Mathematical Archetypes of Nature, Art, & Science. HarperCollins Publishers.
About Ryan L Buchanan
I am training as a Software Developer, Data Analyst & Machine Learning Engineer. I
am currently enrolled in the Software Technology program at Ogden-Weber Technical College. I am also
acquiring certifications as an ML Engineer & Algorithmic Trader from Udacity.
I have a Masters in Data Analytics, an MBA & an MS in Instructional Design. I have
working knowledge of C#, R, SQL, HTML, CSS, Javascript, Java and Python programming
languages.
I have a multi-displinary background including military intelligence,
psychology, linguistics, economics, virtual reality & educational technology. I have
worked abroad for ten years with military, universities & vocational schools.
I have working knowledge of Arabic, Chinese & French. I am very
mobile, able to relocate quickly, adapt easily to diverse working conditions
& have a current passport.
I have a passion for mathematics, statistics & artificial intelligence.
I am enthusiastic, highly self-motivated & enjoy presenting informative data
to decision makers. I am eager to work with dynamic teams to create
high quality products & services.